THE education site for computer science and ICT
2. ASCII and UTF-8 applied to cipher
The most common modern character set is utf-8 which uses the same character codes as the early ASCII character set.
UTF-8 maps each letter of the alphabet to a number called its 'ordinal'. For example the lower case letter 'b' is ordinal 98 and the upper case letter 'Z' is 90
These are the ordinals for upper and lower cases:
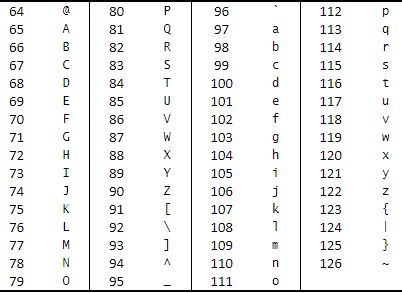
Therefore to swap a letter for an offset one, the key can be added or subtracted from its ordinal to get the encrypted letter.
To encrypt
For example, 'W' and key -2.
W is ordinal 87, subtract the key (-2) to get ordinal 85 (U). This is the cipher character.
To decrypt
Reverse the arithmetic. If the cipher is 'U' (ordinal 85), then reverse the key (+2), and so the decrypted character is 'W' (ordinal 87)
Keep in range
The only tricky bit is that the ordinals have to stay in the ranges for a-z ( ordinal 97-122) and A-Z (ordinal 65-90). There are 26 letters in the alphabet, this is used to bring ordinals back in range.
This is quite simple to do - for letters a-z, if ordinal is less than 97 (a) add 26 to it to bring it back in range. If the ordinal is greater than 122 (z) then subtract 26 to bring it back in range.
For the letters A-Z, the rule is similar. If ordinal is less than 65 add 26 to get the converted letter. If the ordinal is greater than 90 then subtract 26.
Example
Say you need to encrypt the letter B (ordinal 66) with key -10.
The new ordinal is 66 - 10 = 56. This is less than 65 and outside the A-Z range, so add 26 to it, 56+26 = 82 (R) which is the encrypted letter.
To decrypt, add +10 to 82 and you get 92, this is above the range, subract 26,
92-26 = 66, which is 'B' once more.